
A Delay Modeling Framework for Embedded Virtual Network Function Chains in 5G Networks
Qiang Ye, Weihua Zhuang, Department of Electrical and Computer Engineering, University of Waterloo, Waterloo, Canada
{q6ye, wzhuang}@uwaterloo.ca
Xu Li, Jaya Rao, Huawei Technologies, Ottawa, Canada
{Xu.LiCA, jaya.rao}@huawei.com
IEEE Future Networks Tech Focus: Volume 3, Issue 1, March 2019
Abstract
With the development of software-defined networking (SDN) and network function virtualization (NFV), software-defined topology (SDT) design poses technical challenges in embedding virtual network function (VNF) chains to minimize the embedding cost under packet delay constraints. In this article, we present a novel E2E delay modeling framework for embedded VNF chains to facilitate the delay-aware SDT design. A resource allocation policy called dominant-resource generalized processor sharing (DR-GPS) is applied among multiple VNF chains embedded on a common physical network path to achieve dominant resource allocation fairness and high system performance. An approximated M/D/1 queueing network model is then developed to analyze the average E2E packet delay for each traffic flow traversing an embedded VNF chain.
1. Introduction
The fifth generation (5G) communication networks are evolving to interconnect a massive number of miscellaneous end devices with diversified service types for Internet-of-Things (IoT) [1]. Machine-to-machine (M2M) communication services and high data rate broadband services are two typical IoT service categories with different traffic statistics and customized end-to-end (E2E) delay requirements. To accommodate an increasing traffic volume from massive IoT devices with differentiated quality-of-service (QoS) demands, the number of network servers providing different functionalities, e.g., firewalls, domain name system (DNS), needs to be increased for boosted network capacity. However, the densified network deployment largely augments both capital and operational expenditure. Software-defined networking (SDN) [2] and network function virtualization (NFV) [3] are two complementary technologies to enhance global resource utilization and to reduce the network deployment cost for service customization, respectively. For the core network, the SDN control module determines the routing path for each service flow based on global network state information. A service (traffic) flow refers to aggregated traffic from a group of end devices belonging to the same service type and traversing the same source and destination edge switches. On the other hand, a centralized NFV control module exists to orchestrate virtual network functions (VNFs) at appropriate general purpose network servers (also named NFV nodes) to achieve flexible service customization. The SDN and NFV control modules are combined as an SDN-NFV integrated controller for VNF orchestration and placement, and traffic routing decisions. At the service level, each service flow is required to pass through a specific sequence of VNFs to fulfill an E2E service delivery with certain functionality and customized QoS requirement. For example, a DNS service flow traverses a firewall function and a DNS function sequentially. A video traffic flow passes through a firewall function and an intrusion detection system (IDS) for a secured E2E video conferencing. We call a set of VNFs interconnected by virtual links as a VNF chain. Software-defined topology (SDT) design studies how to embed each VNF chain onto the physical substrate network to minimize the VNF deployment and operational cost [4].
2. Delay-Aware SDT Design
For the SDT design, a joint routing and VNF placement problem can be formulated as a mixed integer linear programming (MILP) problem, and a low complexity heuristic algorithm is proposed to solve the problem [4]. The SDT output is the optimal VNF placement on NFV nodes and the optimal traffic routing paths among embedded VNFs. There is an essential tradeoff between minimizing the embedding cost and satisfying the E2E packet delay requirements. To reduce the embedding cost and improve the resource utilization, different VNF chains are preferred to be embedded on a common physical network path with multiple VNFs operated on an NFV node, as shown in Fig. 1. However, the E2E packet delay for each embedded VNF chain can be degraded as it shares both computing and bandwidth resources with other VNF chains.
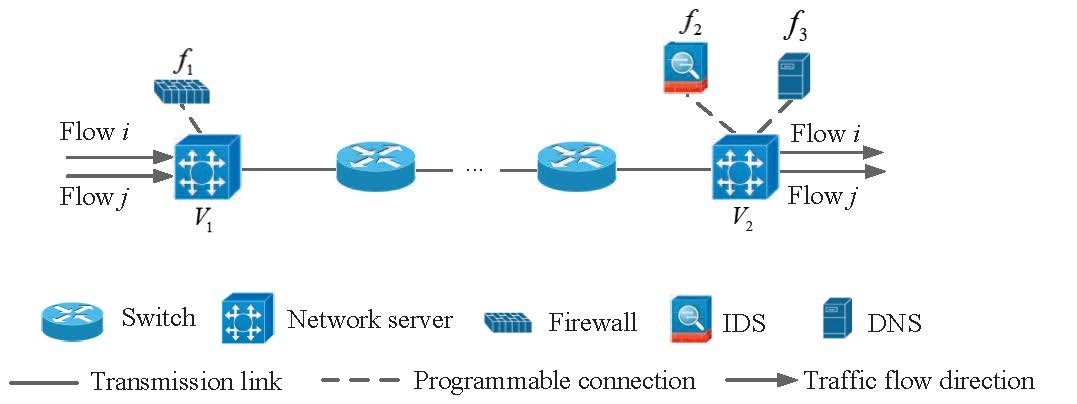
Figure 1: Multiple VNF chains embedded on a common physical network path.
Existing studies model the E2E packet delay of a traffic flow traversing an embedded VNF chain as the summation of packet transmission delays over each embedded virtual link, without considering the packet processing delay at each NFV node [3], [5]. As a matter of fact, when each packet of a traffic flow traverses an embedded VNF on an NFV node, the packet requires an amount of CPU processing time for certain functionality and an amount of packet transmission time on the outgoing link sequentially. Depending on the type of traversed VNF and the type of service that each flow belongs to, different flows have discrepant time consumption for both CPU processing and link transmission. Some small packets with large header size (e.g., DNS request packets) demand more CPU processing time, whereas other packets with large packet size (e.g., video packets) consume more link transmission time. Therefore, how to allocate both computing and bandwidth resources among the flows traversing the VNF(s) embedded on a common NFV node needs investigation, which affects the packet delay of each flow. More importantly, a comprehensive E2E delay model for packets of a service flow passing through each embedded VNF chain should be established, with the joint consideration of packet processing delays on NFV nodes and packet transmission delays on physical links and network switches (see details in Section III), to achieve delay-aware SDT design.
3. E2E Packet Delay Modeling
When traversing an embedded VNF, each traffic flow, say flow i, requires different amounts of packet processing time and packet transmission time, denoted by [ti,1,ti,2]. We refer to this time vector as time profile. We define the resource type that a traffic flow consumes more in processing or transmitting one packet as dominant resource. Since different service flows have discrepant time profiles when passing through the VNF(s) on an NFV node, a dominant resource generalized processor sharing (DR-GPS) scheme [6] is employed to allocate the CPU processing resources and the transmission bandwidth resources among different flows. Compared with GPS [7], the DR-GPS is a promising strategy in the context of bi-resource allocation to balance the trade off between fair allocation and high resource utilization. If GPS is directly applied for the bi-resource allocation (i.e., bi-resource GPS), where both processing and transmission rates are equally partitioned among different service flows, the system performance can be degraded due to the discrepancy of time profiles of different flows. In DR-GPS, the fractions of dominant resources allocated to multiple backlogged flows at an NFV node are equalized to ensure the allocation fairness on the dominant resource types (i.e. dominant resource fairness). The fraction of non-dominant resources is allocated to each backlogged flow in proportional to its time profile to eliminate the packet queueing delay before link transmission. When a traffic flow at an NFV node has no packets waiting for processing and transmission, its allocated resources are redistributed among other backlogged flows according to DR-GPS, to improve resource utilization via traffic multiplexing. With the DR-GPS, the processes of packets from each flow traversing the first NFV node V1 of an embedded network path can be modeled as a tandem queueing system, as shown in Fig. 2, where a set of flows traverse V1 and the traffic arrival process for flow i is modeled as a Poisson process with the arrival rate ɣi. The processing and transmission rates allocated to flow i are ri,1 and ri,2, where we have ri,1 =ri,2 according to the DR-GPS. Thus, there is no packet queueing before the link transmission, and packet queueing exists only before the CPU processing.
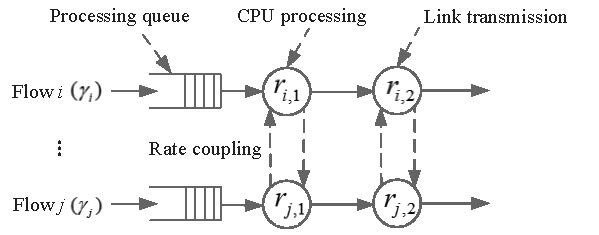
Figure 2: A tandem queueing model for traffic flows traversing V1.
Given the set of flows multiplexing at an NFV node, the instantaneous packet processing rate of a tagged flow varies among a set of discrete rate values, depending on the non-empty queueing states of the other flows. This rate correlation makes the queueing analysis intractable for delay calculation. For tractability, we calculate the average packet processing rate for each flow by taking into account the processing queue non-empty probabilities of all the other traffic flows (i.e., exploiting the traffic multiplexing gain), which is used as an approximation of decoupled packet processing rate for the flow [1]. Then, a decoupled queueing model for packet processing of each traffic flow at V1 is established, where the decoupled processing rate for flow i is denoted by di,1, as shown in Fig. 3. To further decouple the transmission rate correlation, we analyze the packet departure process from each decoupled processing at V1. Let Xi be the packet inter-departure time of flow i at the decoupled processing of V1. Due to the Poisson characteristics of the packet arrival process, a departing packet sees the same steady-state queue occupancy distribution as an arriving packet [8]. Therefore, if the mth departing packet sees a non-empty queue, we have Xi = Ti, where 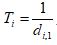 ; if the packet sees an empty queue, we have Xi = Ti+Yi, where Yi is the duration from the mth packet departure instant to the arrival instant of the (m+1)th packet of flow i.
; if the packet sees an empty queue, we have Xi = Ti+Yi, where Yi is the duration from the mth packet departure instant to the arrival instant of the (m+1)th packet of flow i.
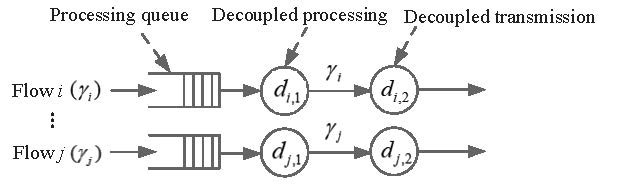
Figure 3: A queueing model for decoupled packet processing and transmisson [1].
Due to the memoryless property, Yi follows the same exponential distribution as the packet inter-arrival time. Therefore, the probability density function (PDF) of Xi can be calculated as
![]()
where ![]() , and
, and ![]() are the PDFs of Yi+Ti and Ti , respectively. As Ti and Yi are independent variables,
are the PDFs of Yi+Ti and Ti , respectively. As Ti and Yi are independent variables, ![]() can be calculated as the convolution of the PDFs of Yi and Ti [1]. Then, the cumulative distribution function (CDF) of Xi, and its mean and variance are further expressed as [1]
can be calculated as the convolution of the PDFs of Yi and Ti [1]. Then, the cumulative distribution function (CDF) of Xi, and its mean and variance are further expressed as [1]
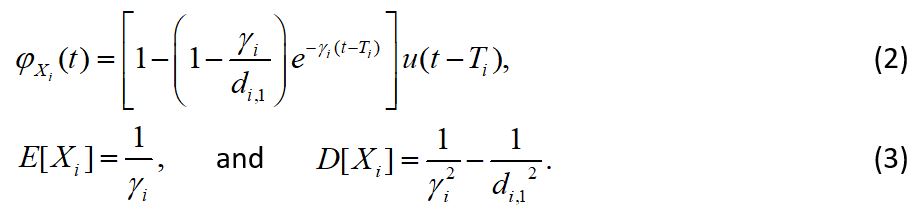
Eq. (2) and Eq. (3) indicate that the packet inter-departure process from the decoupled processing is a general process between a Poisson process and a deterministic process, with the average departure rate ɣi. Therefore, by using the same method as the processing rate decoupling, we calculate the decoupled packet transmission rate for flow i as di,2, where di,2= di,1. This is because the instantaneous processing and transmission rates are equalized according to DR-GPS, i.e., ri,1 =ri,2, and the average departure rate from each decoupled processing is same as the arrival rate. With the completely decoupled queueing model for both packet processing and packet transmission, the average packet delay, Di,1, for traffic flow i traversing the first NFV node can be determined [1], including packet queueing delay before processing, decoupled packet processing delay, and decoupled packet transmission delay, according to the M/D/1 queueing analysis.
Before modeling the delay of packets traversing the second NFV node V2, we first analyze the packet departure process from the decoupled link transmission of flow i at V1, which is derived as the same general process with the departure process from the decoupled processing (Analytical details are provided in [1]). The process approaches a Poisson process when ɣi is small and a deterministic process when ɣi is large. Packets from each decoupled outgoing link transmission are then forwarded through a number of network switches and physical links before arriving at the subsequent NFV node. According to Proposition 1 in [1], the packet arrival process of a traffic flow at V2 is the same as the departure process from V1, as long as the transmission rate allocated to the flow at each traversed network switch and link is greater than or equal to the decoupled transmission rate at V1. In this way, no queueing delays are incurred on switches and links, and the bandwidth utilization is maximized. The delay over the embedded virtual links between V1 and V2 can be calculated as the summation of packet transmission delays over network switches and physical links between V1 and V2 [1]. Since the packet arrival process of each flow at V2 is the same general process in between a Poisson process and a deterministic process with the average rate ɣi, we decouple the processing and transmission rates for flow i at V2, similar to the rate decoupling at V1. The decoupled rates are denoted by di,1 and di,2, as shown in Fig. 4, where di,1 = di,2.
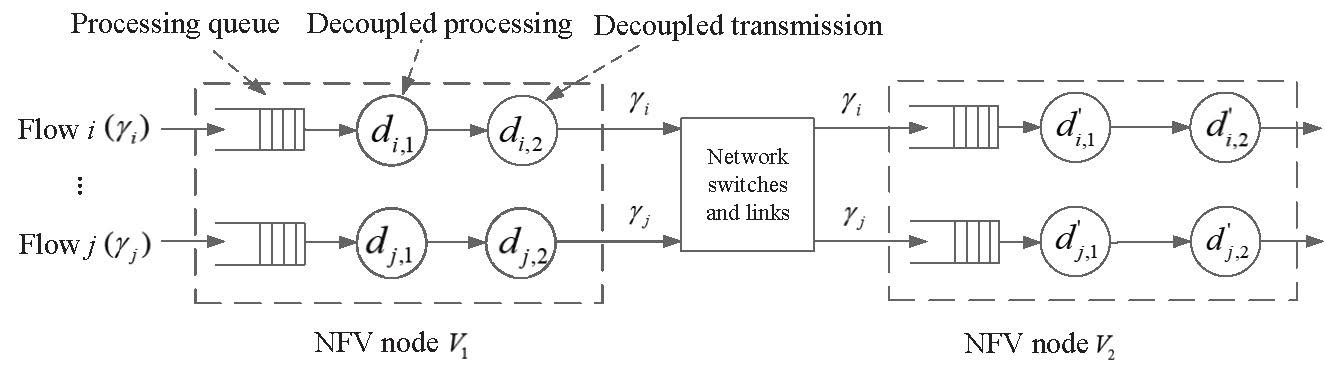
Figure 4: A decoupled queueing model for traffic flows traversing V1 and V2 in sequence.
Since the traffic arrival process at V2 correlates with the packet processing and transmission at V1, a G/D/1 queueing model is not accurate for calculating the delay of packets going through each decoupled processing at V2, especially when ɣi is large [8]. For the case of di,1 < di,2, the traffic arrival process of each flow at V2 is more likely to approach a Poisson process with the varying rate parameter ɣi under the queue stability condition [1]. For the case of di,1 ≥ di,2, there is no queueing delay for packet processing at V2. We approximate the packet arrival process of each flow at V2 as a Poisson process with rate parameter ɣi , and establish an M/D/1 queueing model to determine the average queueing delay before processing at V2. Proposition 2 in [1] indicates that the average packet queueing delay, based on the approximated M/D/1 queueing model, provides a more accurate upper bound than that using the G/D/1 queueing model under both lightly- and heavily-loaded input traffic. Therefore, the approximated average packet delay Di,2 , for traffic flow i traversing V2 can be determined [1].
In general, the same queueing modeling methodology can be applied independently at each subsequent NFV node (if any) along the embedded network path, upon which an approximated M/D/1 queueing network is established to calculate the E2E packet delay for each embedded VNF chain. With the proposed analytical E2E packet delay modeling, the delay-aware SDT design can be achieved as illustrated in the flowchart in Fig. 5. First, multiple VNF chains for different E2E service requests are pre-embedded on the substrate network. Then, our proposed delay modeling framework is applied to determine the E2E packet delay for traffic flows traversing the embedded VNF chains. If the E2E packet delay constraints for the flows are satisfied, the delay-aware VNF chain embedding process is completed; otherwise, the VNF chain pre-embedding phase is revisited and the whole process is repeated until delay-aware SDT is achieved.
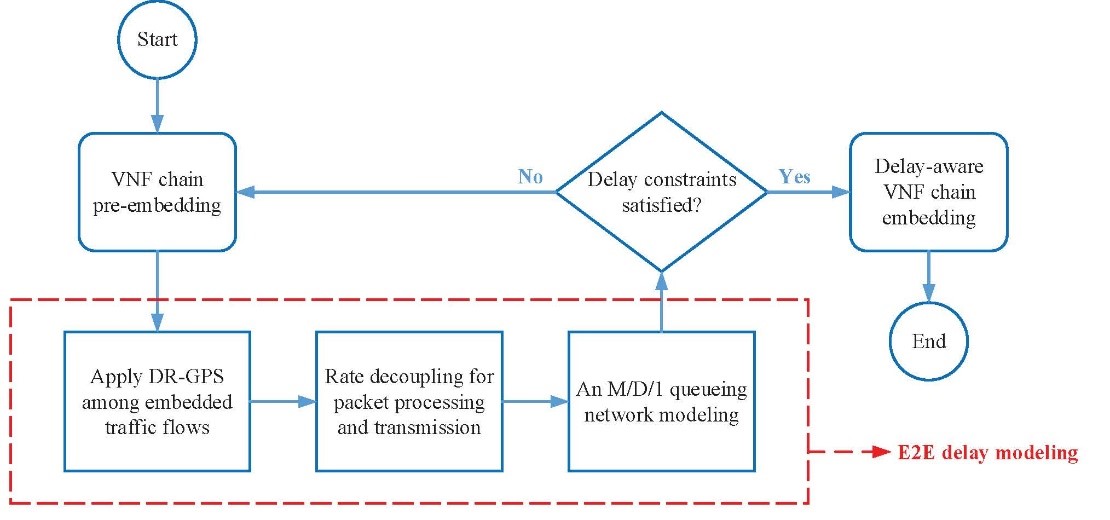
Figure 5: A diagram illustrating the delay aware SDT design process.
4. Simulation Results
In this section, simulation results are provided to verify the accuracy of the proposed E2E packet delay modeling for embedded VNF chains. All simulations are conducted using OMNeT++ [9]. We consider two VNF chains embedded over a common physical network path, as shown in Fig. 1, where flow i traverses f1 and f2 and flow j traverses f1 and f2. We test time profiles of the service flows traversing different VNFs over OpenStack [10], a resource virtualization platform for VNF chain orchestration. The testing results and other simulation settings are referred in [1]. We verify the effectiveness of the proposed rate decoupling and delay modeling methods at each NFV node. Packet queueing delay for one of the flows (flow j) before processing at V1 is shown in Fig. 6. It can be seen that the queueing delay derived using the rate decoupling method is close to the simulation results with rate coupling. Packet queueing delay for flow j at V2 is evaluated in Fig. 7, where the queueing delay derived based on the approximated M/D/1 queueing model achieves a much tighter upper bound than that using the G/D/1 queueing model.
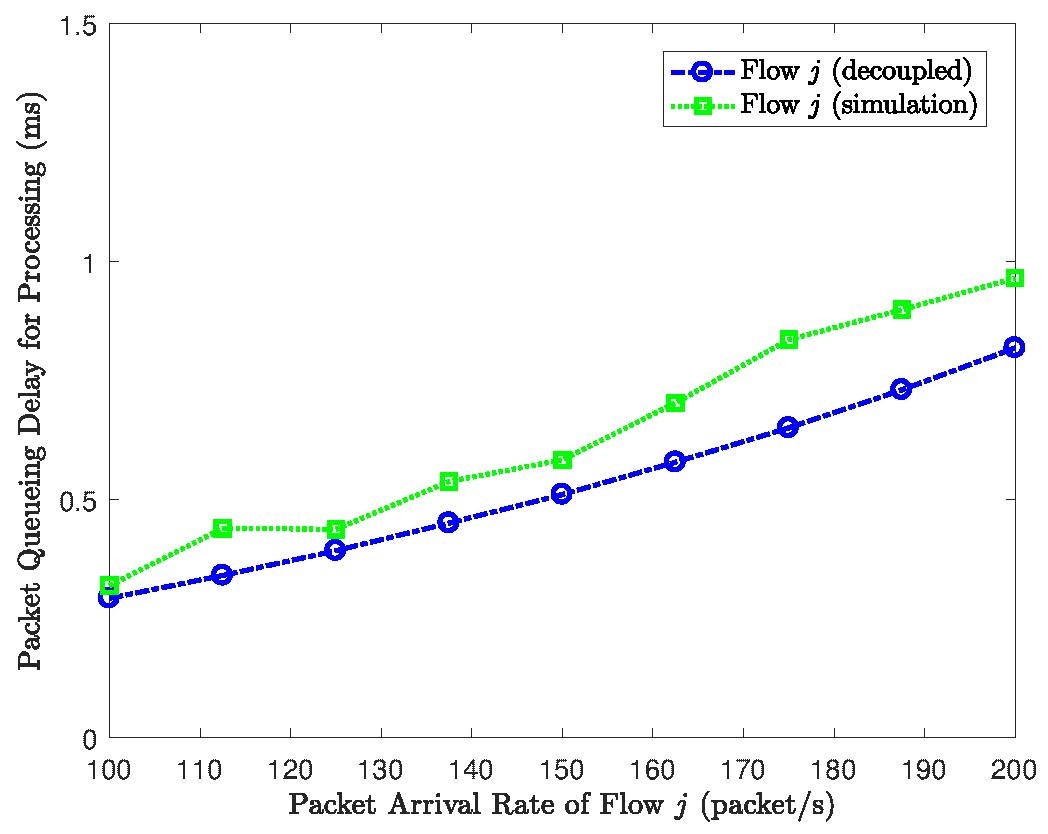
Figure 6: Average packet queueing delay for processing at V1.
5. Conclusion
In this article, an E2E packet delay modeling framework is established for embedded VNF chains over the 5G core network to facilitate delay-aware SDT design. For the VNF chains sharing resources over a common embedded physical network path, the DR-GPS scheme is employed to allocate the computing resources on network servers and bandwidth resources on outgoing transmission links to achieve dominant resource allocation fairness and high resource utilization. With DR-GPS, an approximated M/D/1 queueing network model is established to analyze the E2E packet delay for traffic flows passing through each embedded VNF chain, which is proved to be more accurate than the G/D/1 queueing model for flows traversing each subsequent NFV node following the first NFV node. Simulation results demonstrate the accuracy and effectiveness of the proposed E2E delay modeling framework, upon which delay-aware SDT can be achieved.
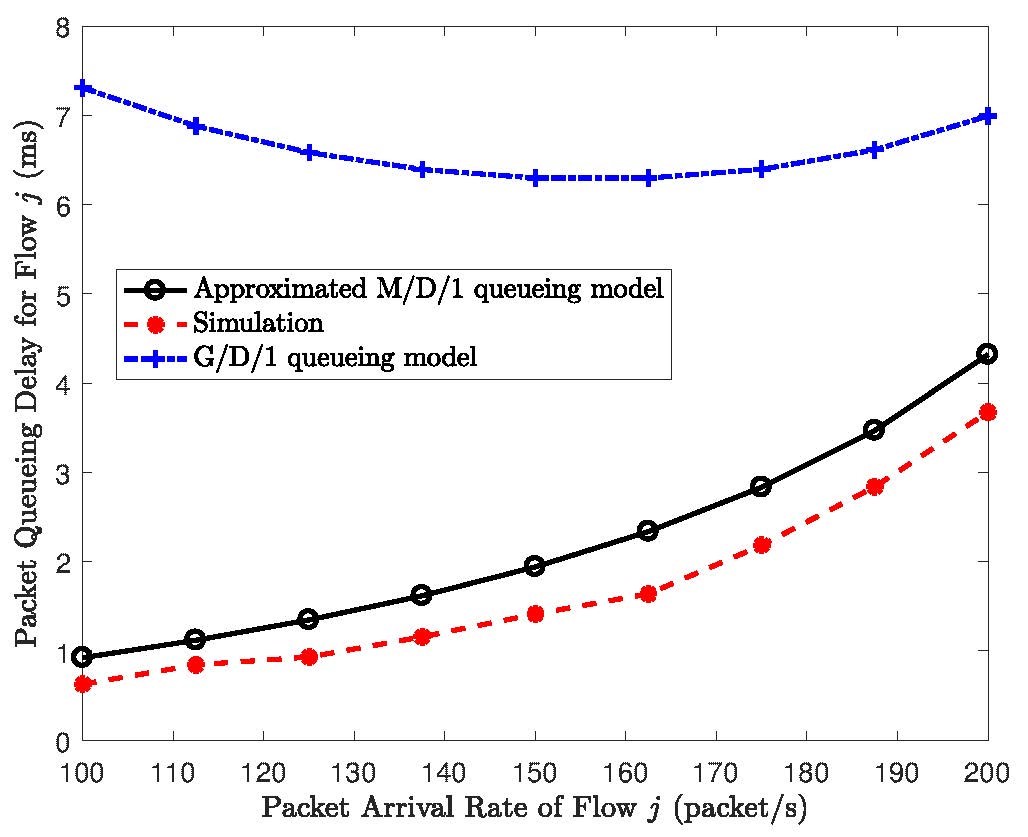
Figure 6: Average packet queueing delay for processing at V2.
Acknowledgement
This work was supported by research grants from Huawei Technologies Canada and from the Natural Sciences and Engineering Research Council (NSERC) of Canada.
References
[1] Q. Ye, W. Zhuang, X. Li, and J. Rao, “End-to-end delay modeling for embedded VNF chains in 5G core networks,” IEEE Internet Things J., to appear, doi: 10.1109/JIOT.2018.2853708.
[2] W. Xia, Y. Wen, C. H. Foh, D. Niyato, and H. Xie, “A survey on software-defined networking,” IEEE Commun. Surv. Tutor., vol. 17, no. 1, pp. 27–51, First Quarter 2015.
[3] F. Bari, S. R. Chowdhury, R. Ahmed, R. Boutaba, and O. C. M. B. Duarte, “Orchestrating virtualized network functions,” IEEE Trans. Netw. Serv. Manage., vol. 13, no. 4, pp. 725–739, Dec. 2016.
[4] O. Alhussein, P. T. Do, J. Li, Q. Ye, W. Shi, W. Zhaung, and X. Shen, “Joint VNF placement and multicast traffic routing in 5G core networks,” in Proc. IEEE GLOBECOM’18, to appear.
[5] L. Wang, Z. Lu, X. Wen, R. Knopp, and R. Gupta, “Joint optimization of service function chaining and resource allocation in network function virtualization,” IEEE Access, vol. 4, pp. 8084–8094, Nov. 2016.
[6] W. Wang, B. Liang, and B. Li, “Multi-resource generalized processor sharing for packet processing,” in Proc. ACM IWQoS’ 13, Jun. 2013, pp. 1–10.
[7] A. K. Parekh and R. G. Gallager, “A generalized processor sharing approach to flow control in integrated services networks: The single-node case,” IEEE/ACM Trans. Netw., vol. 1, no. 3, pp. 344–357, Jun. 1993.
[8] D. P. Bertsekas, R. G. Gallager, and P. Humblet, Data networks. Englewood Cliffs, NJ, USA: Prentice-hall, 1987, vol. 2.
[9] “OMNeT++ 5.0,” [Online]. Available: http://www.omnetpp.org/omnetpp.
[10] “Openstack (Release Pike),” [Online]. Available: https://www.openstack.org.

Qiang Ye (S’16-M’17) received his Ph.D. degree in electrical and computer engineering from the University of Waterloo, Waterloo, ON, Canada, in 2016. He is currently a Research Associate with the Department of Electrical and Computer Engineering, University of Waterloo, where he had been a Post-Doctoral Fellow from Dec. 2016 to Nov. 2018. His current research interests include AI and machine learning for future wireless networking, IoT, SDN and NFV, network slicing for 5G networks, VNF chain embedding and end-to-end performance analysis.

Weihua Zhuang (M’93-SM’01-F’08) has been with the Department of Electrical and Computer Engineering, University of Waterloo, Waterloo, ON, Canada, since 1993, where she is a Professor and a Tier I Canada Research Chair in Wireless Communication Networks. She is the recipient of 2017 Technical Recognition Award from IEEE Communications Society Ad Hoc & Sensor Networks Technical Committee, and a co-recipient of several best paper awards from IEEE conferences. Dr. Zhuang was the Editor-in-Chief of IEEE Transactions on Vehicular Technology (2007-2013), Technical Program Chair/Co-Chair of IEEE VTC Fall 2017 and Fall 2016, and the Technical Program Symposia Chair of the IEEE GLOBECOM 2011. She is a Fellow of the IEEE, the Royal Society of Canada, the Canadian Academy of Engineering, and the Engineering Institute of Canada. Dr. Zhuang is an elected member in the Board of Governors and VP Publications of the IEEE Vehicular Technology Society. She was an IEEE Communications Society Distinguished Lecturer (2008-2011).

Xu Li is a staff researcher at Huawei Technologies Inc., Canada. He received a Ph.D. (2008) degree in computer science from Carleton University. His current research interests are focused in 5G system design and standardization, along with 90+ refereed scientific publications, 40+ 3GPP standard proposals and 50+ patents and patent filings. He is/was on the editorial boards of the IEEE Communications Magazine, the IEEE Transactions on Parallel and Distributed Systems, among others. He was a TPC co-chair of IEEE VTC 2017 (fall) – LTE, 5G and Wireless Networks Track, IEEE Globecom 2013 – Ad Hoc and Sensor Networking Symposium.

Jaya Rao (M'14) received his Ph.D. degree from the University of Calgary, Canada, in 2014. He is currently a Senior Research Engineer at Huawei Technologies Canada, Ottawa. Since joining Huawei in 2014, he has worked on research and design of CIoT, URLLC and V2X based solutions in 5G New Radio. He has contributed for Huawei at 3GPP RAN WG2, RAN WG3, and SA2 meetings on topics related to URLLC, network slicing, mobility management, and session management.
Editors: Chih-Lin I and Haijun Zhang
Subscribe to Tech Focus
Join our IEEE Future Networks Technical Community and receive IEEE Future NetworksTech Focus delivered to your email.
Article Contributions Welcome
Submit Manuscript via Track Chair
Author guidelines can be found here.
Other Future Networks Publications
IEEE Future Networks Tech Focus Editorial Board
Rod Waterhouse, Editor-in-Chief
Mithun Mukherjee, Managing Editor
Imran Shafique Ansari
Anwer Al-Dulaimi
Stefano Buzzi
Yunlong Cai
Zhi Ning Chen
Panagiotis Demestichas
Ashutosh Dutta
Yang Hao
Gerry Hayes
Chih-Lin I
James Irvine
Meng Lu
Amine Maaref
Thas Nirmalathas
Sen Wang
Shugong Xu
Haijun Zhang
Glaucio Haroldo Silva de Carvalho